A few weeks ago I rolled out a feature on the Indeed mobile site that used a modal menu. A coworker noticed that the modal was breaking the back button. Opening and closing the modal was creating entries in the browser’s history.
At first I thought I had missed a preventDefault in a callback somewhere. Nope.
The culprit was an iframe that we were using to track user interactions. If you modify the src attribute, a load event fires inside the iframe. This event bubbles up to the top window, creating a history entry without changing the outermost url.
This fiddle demonstrates the behavior. Click the button and watch your favicon (if you’re in chrome). You’ll see that it spins ever so briefly even though the outermost page does not refresh.
Anyway, I replaced the old iframe hack with Closure’s `goog.net.XhrIo.send` and it was all gravy. If you’re feeling lucky, download the app and you may end up in the modal test group.
PS: If you’re in a situation where you have to use an iframe, but you don’t want to modify the history, just destroy it and create a new one.
For my senior design project I built a system with a few friends to track Android phones indoors using Wi-Fi signal strength. The technique we used is called Wi-Fi fingerprinting and has been detailed in a few academic papers [1][2]. A funded startup called Wi-Fi Slam is attempting to commercialize the same concept.
Update 3/23/2013: WifiSLAM has been bought by Apple for $20 million. There’s a lesson here somewhere.
The Product
The Android app looks like this: The web app allows you to track many phones. It looks like this:
Disclaimer: Much of the source is a mess. I wrote the RMA and the mobile UI plotting code.
Background
The project is driven by the fact that GPS performs poorly indoors– the receiver chips just can’t receive reliable signals through roofs. We decided to get around this with Wi-Fi. The original specs called for a personal inertial device built on Texas Instruments hardware. However, we weren’t too keen on designing an original embedded system and the math required to coordinate a gyroscope, accelerometers and e-compass was unpalatable. Our solution is to construct a table of Wi-Fi signal strengths. At many points inside the building, we recorded X-Y coordinates and the RSSI values from each available access point. We could then perform a lookup in this table to find the nearest point and tell the user that he was at that location.
Overview
The design consists of two subsystems. The first is an application on an Android phone, and the second is the Remote Monitoring Application that runs on a web server. The smartphone application sends real-time position information to the RMA. The system overview below enumerates the inputs and outputs of each subsystem and the interaction between them. The mobile application reads Wi-Fi RSSI values and turns them into positional data. The RMA receives these coordinates and plots them on a map in the user’s browser.
System Overview
Android Application
The mobile application is an Android binary that users run on their smartphones. It tracks the mobile phone’s changing position using Wi-Fi fingerprinting. Fingerprinting allows the application to compare current RSSI values from nearby Wi-Fi access points to previously gathered values in a table stored on the mobile device. The stored values correspond to a physical location, thereby providing an accurate position reading. The application constantly displays its computed position on a map and relays that position to the RMA over an available Internet link (Wi-Fi). The position lookup itself is O(n * m) where n is the number of rows in the table and m is the number of access points sensed. Two nested loops compute the dot product[3] between the current RSSI values and those in the table. The point with the minimum difference is considered to be the closest point and sent to the RMA. The interesting code is in Map.java in the PointWithRSSI method.
Android Application
Remote Monitoring Application
The RMA is a node.js web application built on the Express framework. Coordinates are received by the server as JSON-encoded post requests and pushed to the user’s web browser in real time using the socket.io library. The client-side JavaScript component plots these coordinates on an OpenLayers map. It supports an arbitrary number of phones as long as they report a unique device_id. The mobile app code uses the Android ID for this. The server-side code also stores the data received in MongoDB for future use. The original project requirements called for heat maps, but they were not completed. My implementation is hard-coded to the ENS building, but if you want to adapt our code, you’ll find that OpenLayers is pretty easy to work with. It wouldn’t be a stretch to swap out the image. Pay close attention to the bounds in map.js. They define the coordinate system used for plotting. The RMA also includes functionality to help train the mobile app. Clicking at any point on the map displays the XY coordinates of that spot. We entered these values into the trainer app when recording RSSIs.
Remote Monitoring Application
Aftermath
Long story short, we had everything working for the open house. The accuracy was spotty– about 6 meters. It seemed to perform better in the hallway where the access points were installed rather than the rooms. Accuracy may have been improved by recording more points. In the end, it was enough to convince the professors. We ended up winning second place and taking home a modest cash prize. I wore that obnoxious shirt to troll Merwan for requesting business casual attire. It went okay.
Shoutout to Tim’s wife for doing the poster
This project was more of a lesson in project management than anything technical. We had another team member not pictured above because he just didn’t show up to anything. Not even the open house. Early on we made sure his work would be limited to the wholly independent heat map component. Sure enough, it never got completed.
[2] http://dl.acm.org/citation.cfm?id=1451884 [3] The operation done for each BSSID column in the table is: difference += (stored RSSI) ^2 – (stored RSSI * current RSSI). After the outer loop iterates through each row, the minimum difference tells you which row has the XY coordinates you need. This makes sense, but I’m not convinced it’s actually a dot product. Parts of this post were taken from a Testing and Evaluation plan coauthored by Rohan Singhal, Tim Osborne, and Merwan Hade, and myself.
I’ve had the misfortune of becoming acquainted with the seedy, spammy world of affiliate marketing. This misfortune begat several web applications that generate modest amounts of revenue each month. Finding the total revenue is a chore because most marketers run campaigns from several different affiliate networks. When I want to see how much money I’m making, I don’t want to log in to three or four different sites.
To mitigate this mild inconvenience, I built Earnings, an OO-PHP app designed to scrape daily affiliate network earnings from the myriad sites that owe you money. It looks like this:
Source on github
Problem Description
Most affiliate networks don’t have APIs, so earnings data must be scraped from the HTML. Any scraper must get past the login screen and navigate to the earnings page to find the earnings data. This is problematic because the sites change often, breaking the login code and string parsing used to extract the data. Additionally, networks come and go. When there are no offers worth pursuing, marketers will have no need to view the earnings from that particular network. Furthermore, not all marketers work with the same networks. Any solution must make it easy to select which networks that will be scraped.
Solution Overview
This implementation takes advantage of object orientation in PHP5. The server performs the actual scraping in PHP classes that implement the abstract Network class. These classes are responsible for determining whether or not they have retrieved good data. If earnings data is unavailable due to bad credentials or a modified source site, a JSON-encoded error response is sent back to the client. Credentials for each affiliate network are stored server side in networks.json file.
The javascript client makes jQuery POST requests to authenticate with the server and get the data for the earnings list. Application state is maintained in the earnings_state global.
Limitations
I haven’t exposed any server-side methods to grab earnings from individual networks. The client can only grab the entire batch from the getEarnings javascript function. This is problematic because the calls are not multithreaded and it takes about 5 seconds to serially scrape earnings from 3 networks. Changing this wouldn’t be difficult. A little logic in earnings.php just needs to interface with the getEarnings PHP method of the Network class in question. The client could then call them all asynchronously.
Since all the earnings data lives scattered across the web on affiliate network sites and isn’t persisted on the server, it seems more efficient to cut out the PHP altogether and do everything client-side. Credentials could be saved in HTML5 localStorage. The major barrier is finding an elegant way to do cross-domain POST requests.
Finally, the getEarnings method has two date parameters to let the callee select a date range. These are ignored in the three Network classes I’ve written so far. They scrape earnings for the current day no matter what.
Contribute
Right now this app only supports CPAway.com, Copeac.com, and Maxbounty.com. I set it up so that it’s easy to add support for other networks in a modular fashion. To add your own network, do the following:
After watching J. Chris Anderson show off a CouchDB chat app at an Austin Javascript meeting, I figured Couch might be a good fit for my next large project. Building a clone of my own would be a good way to get familiar with the tech. Since I knew my back end would be PHP, I opted for Kore Nordmann’s PHPillow wrapper after reading some good things on StackOverflow.
Here’s the result:
Structural Overview
Client: jQuery runs in the browser, sending messages and polling the server for new ones. Application settings and state are maintained in the global pillowchat object. Functions beginning with “render” read state information from the global and push it into the DOM.
Server: PHP receives POST requests from the client and handles them in chat.php, sending back JSON messages to the client. There are three CouchDB views defined in views.php for performing the following actions:
Getting a list of users
Getting recent messages
Getting the timestamp on a user’s empty message
Implementation Specifics
CouchDB only stores “message” documents. They contain three properties: Username, tripcode, message, and timestamp. Each message includes a password. The server hashes this into a tripcode that allows users to identify each other without registration. Only the hashes are saved. Mouse over usernames in the chat room to see the tripcodes.
Rather than create a separate document to keep track of users’ most recent activity, I just record timestamps in an empty message document. Every time the client polls for new messages, the empty message document for that client is updated with a timestamp. The getUsers function grabs a list of active users by selecting all the empty message documents with timestamps in the last 5 seconds. Since the views are predefined, you can’t change the timestamp in the request sent to CouchDB. Instead, I return all empty messages and use PHP to loop through the response, looking for the most recent. It seems like there should be a better way to do this.
The Stress Test from Hell
The app looked nice and appeared to work pretty well when I roped in some late night facebook lurkers to test it. Feeling confident in my creation, I showed it off to my neighbor @Kmobs while picking up some cookies from his apartment. The app was in no way prepared for his hordes of CyanogenMod followers. The chat appeared to work okay with about 25 people in the room, but became inaccessible almost immediately after.
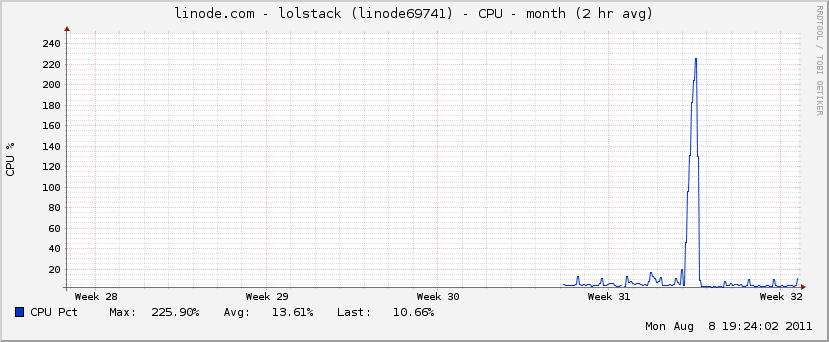
All the polling clients hammered the server, maxing out the Linode instance’s CPU and memory.
It’s obvious that something with an event loop like Node.js would have been far more appropriate here. Apache’s processes quickly wiped out the RAM.
There goes 1/3 of my monthly bandwidth.
Linode provides some nice graphs of CPU, bandwidth, and disk IO. They all confirm that the server was swamped. I’m curious to see how a static web page or WordPress install would stand up to this kind of traffic. The trouble didn’t stop there. During the post mortem I saw that the database size had ballooned to a whopping 5.8 GB.
What had I done wrong? Had I stored the message documents in an inefficient way? Was there some kind of bug causing duplicate documents? Probably not. Here’s what I saw when I wrote a view to dump out all the messages:
Some crafty hackers correctly assumed there was no rate limiting and flooded the chat with long spammy messages. The easiest way to do this is probably Chrome’s javascript console. Some sort of shell script would have also worked.
5,939 MB / 35,800 Documents = 169.9 KB per document
The Takeaway
You already know that you shouldn’t trust clients. This truism is an understatement. You should write your server side code with the assumption that your client code is being manipulated by devious bastards. In this case, the server failed to verify message length and message frequency.
Several improvements could make this app scale better. Websockets are probably better than having clients poll the server every second. When enough people join the chat, the server basically experiences a DDOS attack. Since Websockets don’t really enjoy wide support, the polling method could still be employed in a more conservative manner. Clients could reduce their poll frequency as an inverse function of active users or perform an exponential backoff when their requests time out.
The PHPillow literature base is pretty small. There is a short tutorial on the official site, but it doesn’t cover very many use cases. While the API itself is decently documented, but some more examples would go a long way.
When you create a view in PHPillow, it is stored to CouchDB the first time you execute the code. If you want to modify the view, you must delete the original view in Futon before the changes are stored. This is not a big deal, but it’s frustrating if you don’t know about it. Additionally, I’m not thrilled by the prospect of writing a view every time I want to construct a new type of query. CouchDB is good at selecting ranges, but it’s not immediately apparent how I should locate a document based on 2 string properties, e.g. “firstname=bob&lastname=loblaw”.
The PillowChat source is available on GitHub. It would be fun to see what kind of volume is possible if the aforementioned improvements are implemented. Big thanks to Keyan and the CyanogenMod crowd for the testing.
Edit: You can build a more efficient chat app with far less code using socket.io and node.js. See SocksChat for a simple example.











{kind=link}
{kind=link}
{kind=link}