In The Dark Knight (2008), the Joker destroys a large pile of cash by setting it on fire. This demonstrates the Joker’s commitment to nihilism but raises a much more interesting question: What is the deflationary effect on Gotham’s economy?
To answer that we need to know if the money was actually going to be spent.
It absolutely was.
Before the events of the film, newly elected District Attorney, Harvey Dent, has spearheaded an anti-money laundering campaign but has failed to halt the business of the mob which has access to a few crooked banks under the control of Chinese financier, Lau.
Batman helps his cop friend Gordon identify Lau’s banks via drug purchases with marked bills. Lau’s banks are performing two types of services. The first is exciting: money laundering. The illicit local deposits in Gotham are “layered” by being sent to Lau’s company in Hong Kong and then “integrated” by being paid back to Gotham gangsters. The mob spends this money on the ostensibly legitimate parts of their business like real estate, capital goods (trucks, cement), and payroll which is spent on consumer goods (cannoli).
The other type of service the banks perform is boring: commercial banking. The mob’s deposits are on the books as cash reserves and count toward reserve requirements held against business loans, car loans, and mortgages for the general public. Easy credit helps businesses grow and is great for consumer spending.
Lau’s corrupt cops tip him off to Gordon’s raid and he explains to his ethnically diverse cadre of gangsters that he has moved the deposits to a secure location that is “not a bank”. This is bad for the general public. If the mob is unbanked, there’s slightly less credit available for the people of Gotham.
Remember that the film is set in 2008 which happens to be the beginning of the financial crisis. Gotham needs all the cash it can get.
Later on, the Joker kidnaps Lau and forces him to give up the non-bank location of the money. We see Lau tied up in a chair atop a mountain of cash. Assuming a billion dollars in hundreds is about two pallets, the total value of cash mountain is on the order of 10 billion dollars. Note that Batman had already forced Lau to withdraw the money from the banks so he shares some culpability for the deflation, at least in the short term [1].
Is this a meaningful reduction of the money supply?
WSJ says:
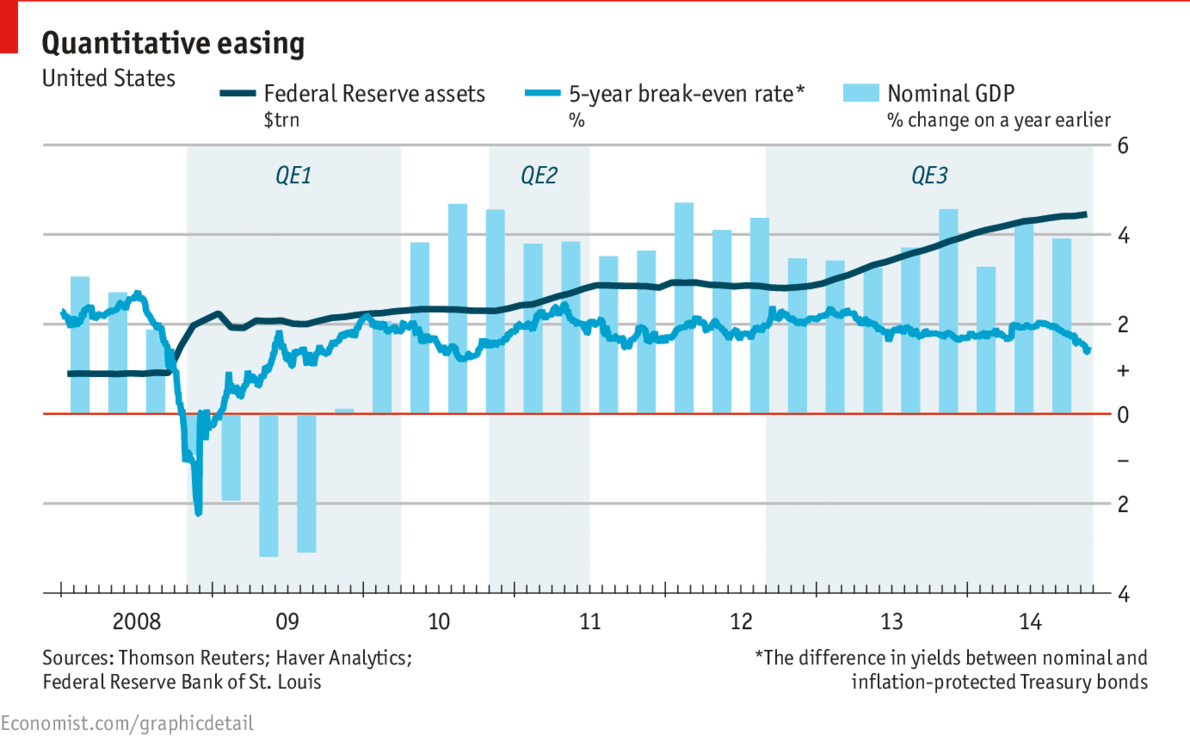
From December 2008 to March 2010, the Fed bought $1.7 trillion of Treasurys and mortgage-backed securities [2]
You can sort of see that here in the dark blue line. Notice the vertical axis is in trillions of dollars [3].
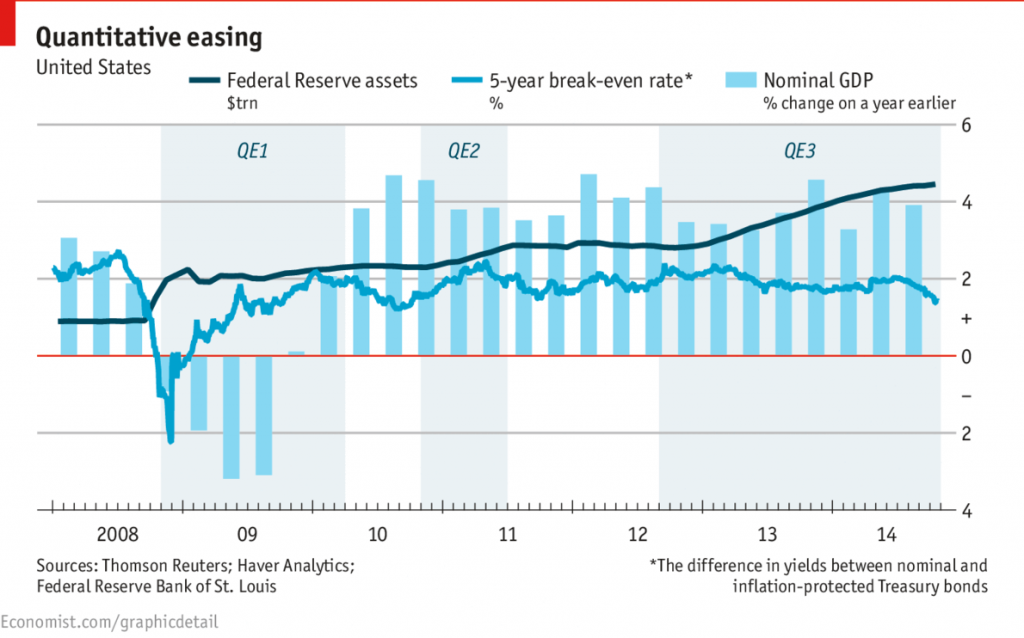
So $1.7T over 15 months is $113B dollars a month. The Joker burned less than a tenth of that in the warehouse which isn’t terrible.
There’s also fallout from dismantling the mob that’s hard to quantify. A nontrivial number of henchmen, goons, and thugs will be out of work if Batman gets his way. These people will have a hard time transitioning to the legitimate economy which systematically practices de jure discrimination against anyone with a criminal record.
But at the same time, the removing the presence of the mob in Gotham lowers costs of doing business for everyone else. If the Taco Bell franchise has to pay protection, it can’t hire a guy to keep the drive-through open on weekends. All told, the mob is probably a net negative for the local economy.
Okay, so burning a few billion dollars isn’t enough to cause serious monetary damage. In fact, it pales in comparison to the non-monetary effects of the Joker’s campaign. Terrorism hurts growth in 2 ways, says the IMF [4].
- Direct damage is physical and logistical. A) Businesses are literally exploded and can’t operate. Remember the hospital destroyed by the Joker. B) Decreased productivity lowers output (the National Guard shuts down all bridges and tunnels)
- Indirect damage is psychological. Decreased consumer confidence lowers consumption. The assassination of the police commissioner isn’t getting anyone into Gotham department stores.
In summary, Batman’s decision to take out the Joker has a sound economic rationale. He’s firmly on the side of growth. See if you can spot the omission in Gordon’s closing remarks.
he’s a silent guardian, a watchful
protector… a dark knight.
What he didn’t say is that he’s a protector of markets. Which isn’t surprising given Bruce Wayne’s nominal day job.
—
[1] Had the total amount been seized by the police under asset forfeiture laws, the cops would get to keep up to 60% for new toys while the remainder goes to the New York state treasury. https://www.ij.org/asset-forfeiture-report-new-york
[2] http://blogs.wsj.com/economics/2010/11/03/qa-on-qe2-what-a-fed-move-would-mean/
[3] http://www.economist.com/blogs/graphicdetail/2014/10/daily-chart-21
[4] http://www.imf.org/external/pubs/ft/wp/2005/wp0560.pdf
Additional reading
Aaron Swartz highlights political and philosophical dilemmas appearing in the film.
http://www.aaronsw.com/weblog/tdk
Screenplay
http://www.pages.drexel.edu/~ina22/splaylib/Screenplay-Dark_Knight.HTM